



The way you ship code speaks volumes about your team. Since every company has a unique environment, every engineering team has different systems—and team culture is often imprinted there. Here I’ll give you a peek into the way we ship code in production at Front. It’s a vast topic, but hopefully will give you some insight into the way our team works, what we value, and what makes us tick.
Shipping code is a compromise.
Changing things carries the inherent risk of breaking things. Not changing anything is equally dangerous: you risk not providing the best possible product to your customers. This predicament has always been especially complex for us at Front:
Front is the main work tool for many of our users. On average, users spend 2.1 hours on Front every day, and any disruption means that they can’t get work done.
Front is also an ongoing experiment: we’re constantly inventing new workflows and adding collaboration in places that we hadn’t originally designed.
It feels like we are navigating uncharted seas: we test plenty of ideas to figure out the ones that will work. When it’s possible, we find the best solution through research. Often, we need to flesh out fully usable features and test them with Fronteers or key customers. We get to use, test, and find bugs in the very tool we’re building—because we’re working in it all day every day. We inevitably make significant changes, and sometimes it doesn’t work out. That’s all part of the process.
This is why iterating quickly is still a necessity even though our product has existed for multiple years: the longer you work on an idea, the more emotionally committed you get.
Spend too much time and you become unable to realize when an idea was great on paper, but doesn’t actually work in the real world.
I don’t believe there’s a single best way to ship code in production, but we’ve found a system that works well for us at Front. Here’s a glimpse at it:
Our release system at a glance
Here are some facts to give you an idea of the scale we’re working with:
We continuously adjust the resources we need based on our customers’ needs, but at peak time, Front spans about 1500 servers running 20,000 processes.
Our current approach is to essentially tear down our entire infrastructure and recreate a new one every time we want to release new code, in a way that is invisible to end users.
We do this across a dozen independent infrastructures located in several countries.
This happens between 20 and 40 times a day: any engineer can trigger a deploy and the process is completely automated.
We use a mix of in-house and external tools (list in appendix if you’re interested). For example, this is the dashboard we use to monitor deployments:
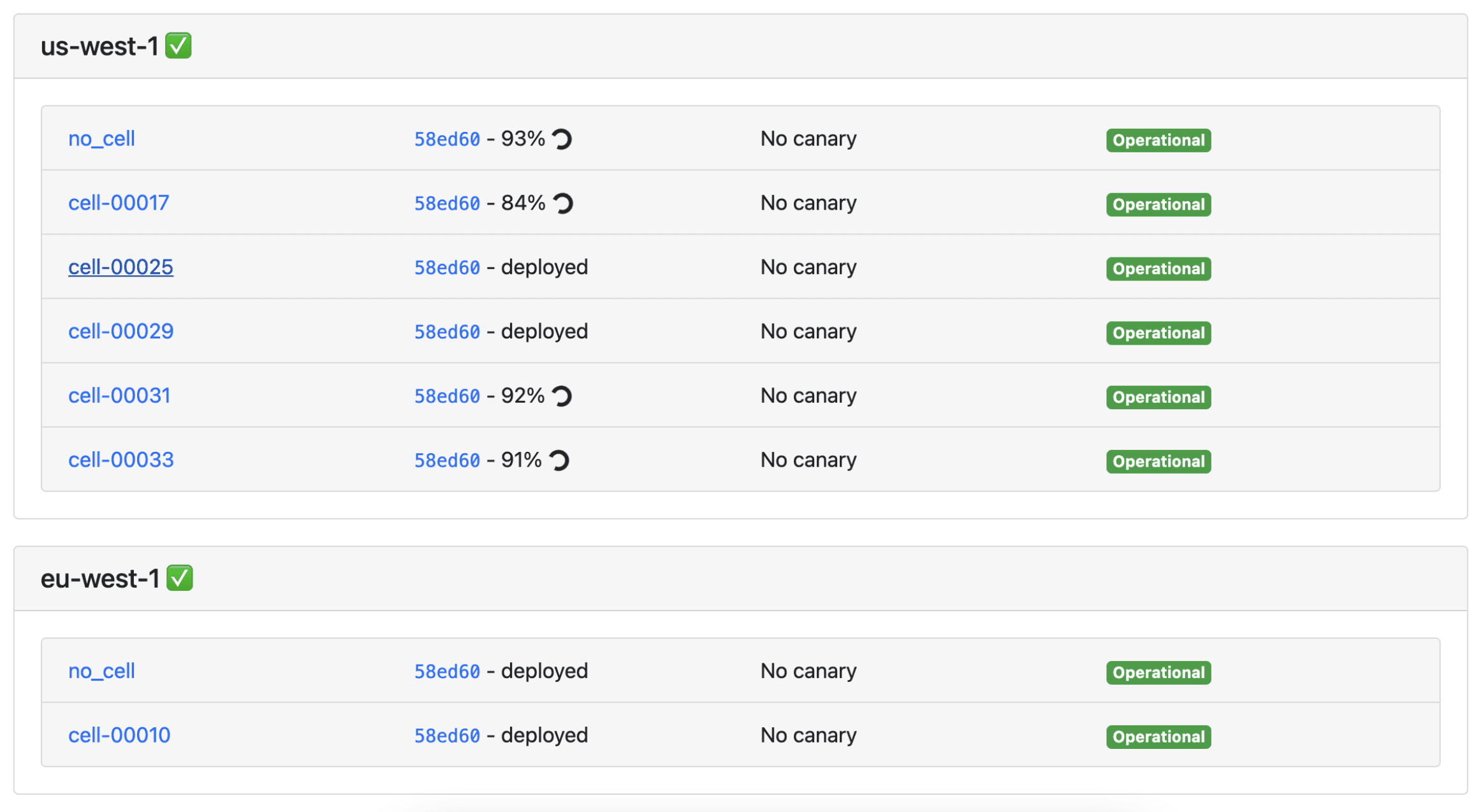
We have the following goals for the way we ship code in production as a team:
Ship as fast and as often as possible.
Blame the system, not individuals.
Release progressively.
Don’t run into the same problem twice.
So, let’s dive in.
1. Ship as fast and as often as possible
Why ship often?
Deploying new code is dangerous: you can’t account for every possibility. No matter how much you test, some interactions only happen at production scale, when Front is used by teams of thousands of users.
Above all else, we never want to improvise, so we need to be in control of our software at all times. Front runs about 150 distributed services. Code is not rolled out instantly, so multiple versions of these services can run concurrently. Keeping changes as small as possible makes it easier to study all the possible interactions.
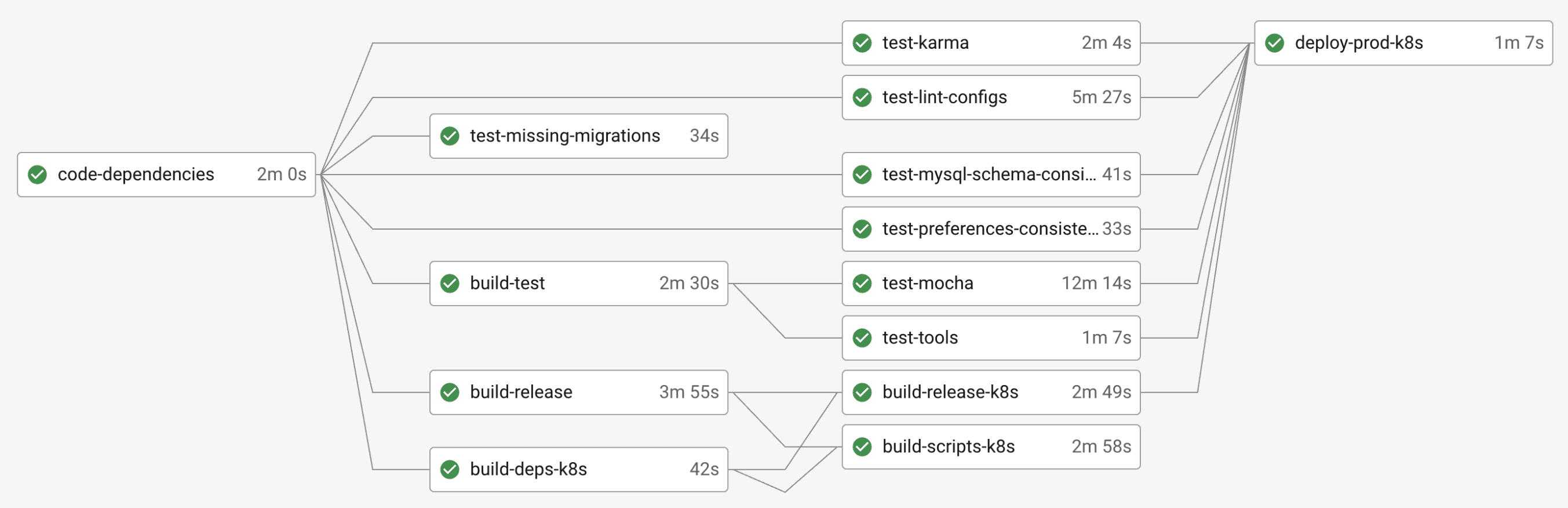
We typically deploy continuously: as soon as one version is fully rolled out, we start the next one. This means that the time it takes to deploy is a main limiting factor, and we have to figure out ways of speeding up our deployment process even as our systems have gotten more and more complex.
Speeding up the deployment pipeline
Front uses an event-driven architecture where events are loosely ordered in a distributed architecture. We run more than a hundred independent services on our servers.
While scaling this system to large teams is already a massive engineering challenge, testing it is another story entirely. Every user interaction results in services talking to each other. This means that having a good unit test coverage of individual services is not enough: we also need to extensively test interactions and race conditions between services. Overall, we run about 15k tests before each deploy.
Over the past two years, we made investments to make our test infrastructure faster. For example, we now use snapshots so different tests can quickly reuse the same mock environment. We also use a lot of concurrency in our pipeline to do many tasks at once.
2. Blame the system, not individuals
When we started Front with a very small team, each engineer ended up owning an uncomfortably large part of the product. We couldn’t wait for the company to grow so we could have more help and offer a better service. But growing your team can actually make things worse if you don’t have the right processes in place: the scale at which we operate magnifies any ambiguity that remains in our procedures. If we don’t constantly work on eliminating it, releasing progressively gets perceived as a dangerous task that only seasoned engineers can do. If you cannot empower your new engineers, there will be a ceiling on how far your team can go.
Ideally, we could build an automated process that can tell us if a pull request is safe to merge. Things are more complex in the real world, however, and not everything can be automated. Some changes require complex data migration over billions of records that sometimes need to run for several weeks. We eventually settled on a mix of automated and manual tools. For example:
We use static code analysis: we use a linter to flag potential issues. On top of the defaults, we maintain custom rules to recognize dangerous patterns that are specific to our codebase.
Any engineer can add special labels on a PR, which block the merge until the author acknowledges that a verification was made, like a partial deploy.
If the PR contains modifications in key connectors, the system will ask the author to run specific tests against production-like data and paste the output in the PR body.
We use checklists where the author must tick checkboxes to acknowledge that all steps have been followed. This helps avoid situations where engineers are not aware that a procedure has changed recently.
We have a system to review, run, and monitor custom scripts that run in our production environment. Engineers have access to a dashboard with currently running scripts.
3. Release progressively
We want to be sure that every aspect of Front is battle-tested before we feel comfortable talking about it. By the time we publicly announce a new feature, it has typically lived in the app for several weeks and is tested by Fronteers or select beta customers first. Initially, the feature will be invisible to almost all users: we use feature flags to enable it to a growing set of users.
This makes operations safer, but it does not solve everything: even if code is supposed to be dormant, you can still run into unexpected interactions. Some changes that need to be rolled to many customers at the same time, like database upgrades. Even if your release system is mostly automated, you cannot avoid exceptions and manual operations. This creates ambiguity, and it gets worse as your team gets bigger.
We have 3 steps for releasing features, which the whole team follows:
1. Run Front on your local environment
We’ve always invested in making it easy to run Front locally. You can run a self-contained, fully-functioning version of Front on a laptop in minutes, without any external dependency. A key choice we made earlier on was building a mock implementation of all the external storage engines required by Front. This means that with relatively few effort, the same code base can run:
Inside a single process node.js process, on a engineer’s computer.
Distributed across thousands of processes, in a cloud environment.
The goal of this local environment is not to provide an exact replica of production, but to get you 99% of the way in a safe, flexible environment. Running Front locally is the first step to shipping code.
2. Deploy Front on your personal staging environment
Once you are confident that your code works on your machine, you can deploy it on your personal staging. Each engineer at Front has a personal Kubernetes cluster: a miniature version of Front running in a cloud environment that is as close as possible to the real production environment. It uses the same deployment pipeline and the same storage engines as the real production. It can also serve to demo a feature to other Fronteers.
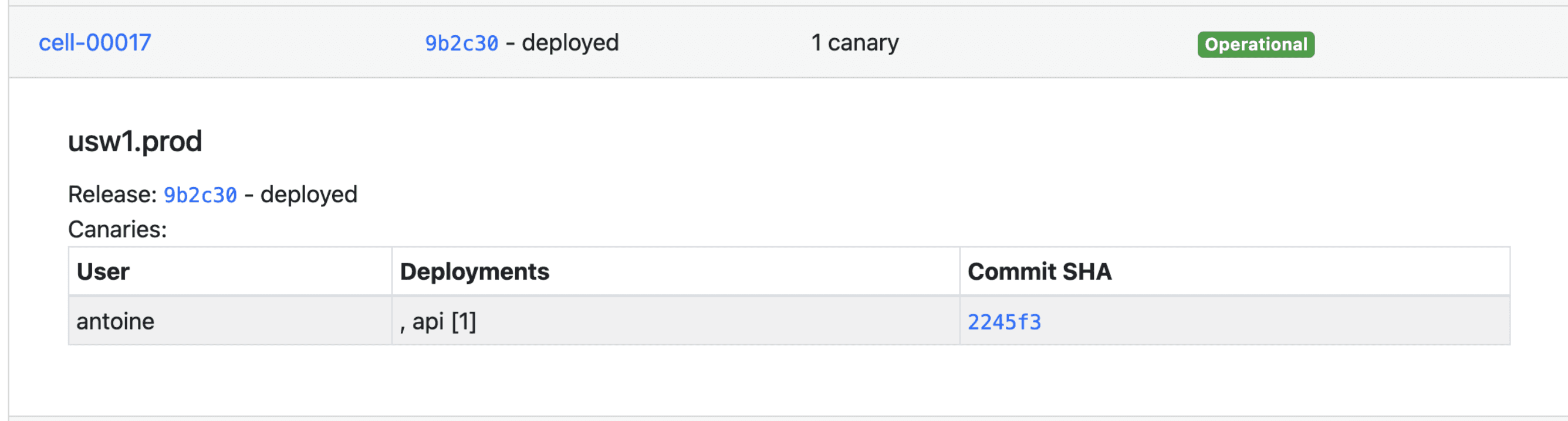
3. Use a canary for testing
Even with extensive tests and easy-to-use environments that are very close to production, there are still problems that will only appear once your code is out in the wild with customers. Most of our code goes through a canary first: we deploy the new code on a handful of processes while we verify that everything is working as expected. We can remove these processes at any time if needed, and only a short fraction of production will go through them. We can run multiple canaries at the same time, and we have internal tools to monitor them.
4. Do not run into the same problem twice
We run post-mortems whenever we run into an issue with the goal that the exact same problem should never happen again. It’s not about fixing one bug: it’s about identifying a class of problems and figuring out which step of our release process should catch it in the future.
To hold ourselves accountable, we send a detailed email about an issue to our customers explaining exactly what went wrong and we intend to do about it. It’s the best way to make sure that you are learning as much as possible. It’s one of the most difficult aspects of my job, but possibly the one with the highest impact. Our customers often email us back telling us they appreciate the honesty and the explanation.
Our tech stack
Finally, these are some of the off-the-shelf tools we use as part of our deployment process:
Kubernetes clusters in several AWS regions.
CircleCI, to run our deployment pipeline.
Github actions and Danger.js, to only allow pull requests that follow our internal rules to be merged.
TypeScript and eslint to enforce our coding standards.
Ship code with us
This is just a peek into the way we ship code to production here at Front. I hope this gives you insight into the way we work together—and how we orient our processes around our customers. If you’re interested in learning more about our engineering team, head over to our jobs page.
Written by Laurent Perrin
Originally Published: 30 June 2021